
新浪博客

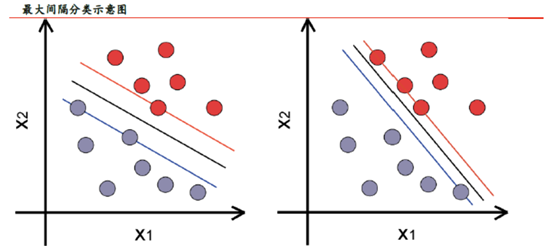
SVM的潜在缺点包括以下方面:需要对输入数据进行完全标记、未校准类成员概率、SVM仅直接适用于两类任务,因此,必须应用将多类任务减少到几个二元问题的算法;解出的模型的参数很难理解。
公司网站:lianghuajijin.com
QQ:3043656568
邮箱:3043656568@qq.com
新浪认证微博:量化基金
联系人:
联系电话:17601010202
关注微信公众号

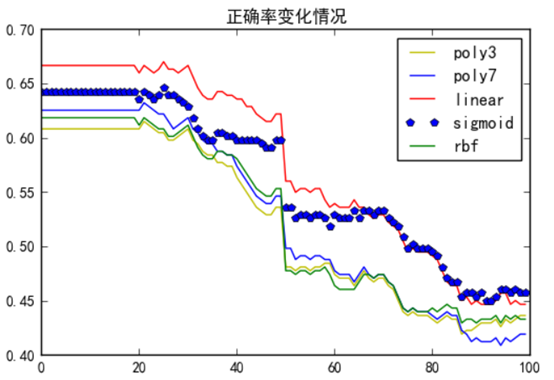
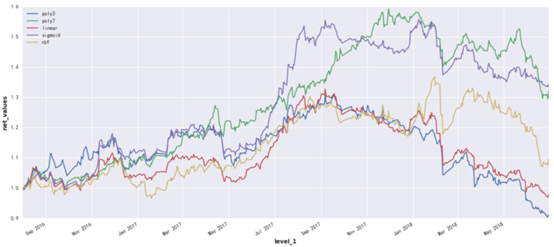
| 核 |
相对收益 |
绝对收益 |
最大回撤 |
| 3阶多项式 |
-15.98% |
-6.39% |
-29.36% |
| 7阶多项式 |
23.77% |
33.35% |
-16.54% |
| 线性 |
-15.71% |
-6.13% |
-27.6% |
| sigmoid |
28.29% |
37.87% |
-15.69% |
| rbf |
-1.09% |
8.49% |
-22.42% |
公司网站:lianghuajijin.com
QQ:3043656568
邮箱:3043656568@qq.com
新浪认证微博:量化基金
联系人:
联系电话:17601010202
关注微信公众号